外观
算力互联HPC自营集群使用说明
2024年4月
自营集群采用CentOS-7.6操作系统,配合Slurm作业调度系统,所有计算资源和存储资源,均可统一调用。
1 用户登录
1.1 登录集群
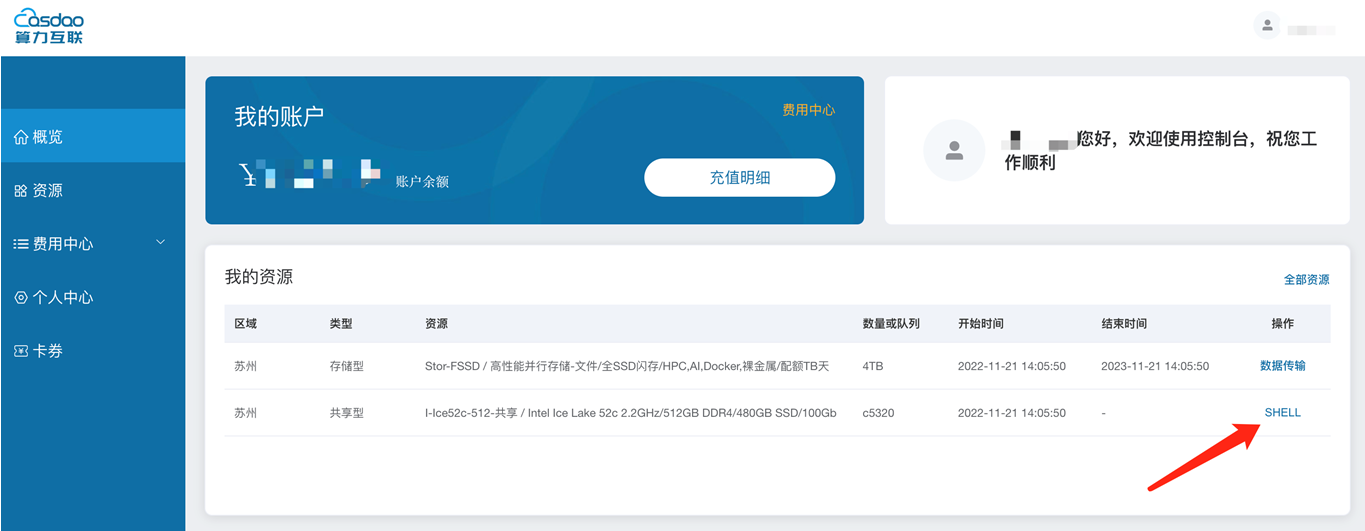
1.2 登录节点信息
| 登录节点 | IP地址 | SSH端口 | 说明 |
|---|---|---|---|
| hnlogin01 | 12.2.1.3 | 22 | 用于用户登录、软件编译等基本操作 |
| hnlogin02 | 12.2.1.4 | 22 | 用于用户登录、软件编译等基本操作 |
说明:
登录节点仅供用户登录和一般操作(拷贝数据上传,文本编辑,程序编译等)使用,不允许在登录节点执行计算任务,管理员或监控程序会不定期杀掉非法的计算进程。
2 环境加载
用户一般需要特定软件环境来运行软件,集群使用environment modules工具(版本3.2.10)来管理软件环境,用户可通过module命令轻松修改所需要的软件环境,常用的命令有:
| module 命令 | 说明 |
|---|---|
| module avail | 查看可用环境名称 |
| module load/add MODULE/NAME/VERSION | 加载“MODULE/NAME”环境 |
| module list | 查看当前已经加载的环境 |
| module unload/rm MODULE/NAME/VERSION | 卸载“MODULE/NAME”环境 |
| module purge | 清空当前加载的所有环境 |
查看可用环境:
bash
[username@hnlogin02 ~]$ module avail #或者module av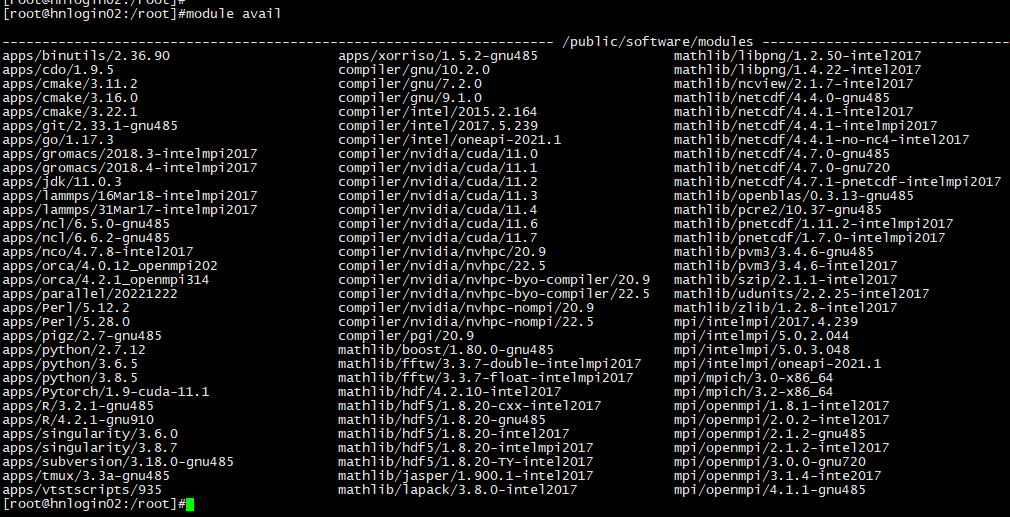
说明:截图为实例,请以集群使用时的module avail 输出准。
加载软件环境:
bash
[username@hnlogin02 ~]$module load compiler/intel/2017.5.239 #或者module add
[username@hnlogin02 ~]$module load mpi/intelmpi/2017.4.239 #加载intelmpi-2017 MPI环境卸载软件环境:
bash
[username@hnlogin02 ~]$ module unload compiler/intel/2017.5.239 #或者 module rm
[username@hnlogin02 ~]$ module purge #清空当前所有加载环境查看已加载环境:
bash
[username@hnlogin02 ~]# module load mpi/intelmpi/2017.4.239
[username@hnlogin02 ~]# module list
Currently Loaded Modulefiles:
1) compiler/intel/2017.5.239 2) mpi/intelmpi/2017.4.239
[username@hnlogin02 ~]#查看环境内容:
bash
[username@hnlogin02 ~]# module show mpi/intelmpi/2017.4.239
-------------------------------------------------------------------
/public/software/modules/mpi/intelmpi/2017.4.239:
module-whatis IntelMPI MPI utilities for IB/intel compiler
module load compiler/intel/2017.5.239
conflict mpi
setenv I_MPI_ROOT /public/software/mpi/intelmpi/2017.4.239
prepend-path PATH /public/software/mpi/intelmpi/2017.4.239/intel64/bin
prepend-path LD_LIBRARY_PATH /public/software/mpi/intelmpi/2017.4.239/intel64/lib
prepend-path MANPATH /public/software/mpi/intelmpi/2017.4.239/man
prepend-path INCLUDE /public/software/mpi/intelmpi/2017.4.239/intel64/include
setenv SLURM_MPI_TYPE pmi2
-------------------------------------------------------------------
[username@hnlogin02 ~]#更详细的使用,请使用man module 来查看帮助文档,或参考:https://modules.sourceforge.net/
3 程序准备
用户作业所需要的软件,一般可分为商业软件、开源软件和自编程序。
•商业软件请参考软件安装文档进行安装和配置license服务或证书。
•开源软件和自编程序,如果未提供通用linux版本的二进制执行程序,需要从源码编译安装。
3.1 程序编译安装
目前,该集群上安装了多个编译器,例如GNU开源编译器、Intel商业版编译器、NVHPC等,可直接加载使用,如果需要添加或升级,可联系管理员技术支持。 常用编译器编译命令:
| 编译器 | GNU命令 | Intel命令 | NVHPC命令 | 常见源码文件后缀 |
|---|---|---|---|---|
| C编译器 | gcc | icc | nvcc | .c |
| C++编译器 | g++ | icpc | nvc++ | .C,.cc,.cpp,.cxx |
| Fortran90编译器 | gfortran | ifort | nvfortran | .f, .for,.ftn |
| Fortran77编译器 | gfortran | ifort | nvfortran | .f90,.fpp |
下面以Intel 编译器为例,介绍一般程序编译的方法。
3.1.1 串行程序编译
串行程序编译方法
| 语言 | 编译器命令 | 常见源码文件后缀 | 常见源代码文件后缀 |
|---|---|---|---|
| C | icc | .c | icc $CFLAGS -o main.exe main.c |
| C++ | icpc | .C,.cc,.cpp,.cxx | icpc $CXXFLAGS -o main.exe main.cpp |
| F90 | ifort | .f, .for,.ftn | ifort $FFLAGS -o main.exe main.f90 |
| F77 | ifort | .f90,.fpp | ifort $FFLAGS -o main.exe main.f |
C 语言编译示例:
bash
[username@hnlogin02 ~]$ icc -xHost -O2 -o main.exe main.cFortran 语言编译示例:
bash
[username@hnlogin02 ~]$ ifort - xHost -O2 -o main.exe main.f90 其中,-xHost -O2为优化选项,-o指定可执行文件名(如果不指定该选项,可执行文件默认a.out),main.c/mainf90为源代码文件名。
更详细的编译器使用方法,可以查看命令帮助或者Intel编译器用户手册。
bash
[username@hnlogin02 ~]$ icc --help
[username@hnlogin02 ~]$ icpc --help
[username@hnlogin02 ~]$ ifort --help3.1.2 多线程并行程序编译
OpenMP是单节点多线程并行计算模式,OpenMP支持的编程语言包括C、C++和Fortran,目前多数编译器都支持OpenMP模式,但选项有所不同。
| 语言 | GNU | Intel |
|---|---|---|
| OpenMP参数 | -fopenmp | -qopenmp |
C 语言OpenMP 程序编译示例:
bash
[username@hnlogin02 ~]$ icc -qopenmp -xHost -O2 -o main.exe main.c3.1.3 MPI并行程序编译
MPI(Message Passing Interface)是跨语言的通讯协议,是目前HPC集群中重要的消息传递并行编程模型。以Intel MPI为例,它提供了完整的MPI编译器:
| Intel MPI编译器命令 | 编译命令说明 |
|---|---|
| mpicc,mpigcc | 使用gcc 编译 C 语言 |
| mpicxx,mpigxx | 使用g++ 编译C++ 语言 |
| mpif77 | 使用g77 编译 Fortran77 语言 |
| mpif90 mpif90 | 使用gfortran编译Fortran90 语言 |
| mpifc | 使用gfortran编译Fortran77/90语言 |
| mpiicc | 使用icc 编译C 语言,推荐使用 |
| mpiicpc | 使用icpc 编译C++ 语言,推荐使用 |
| mpiifort | 使用ifort 编译Fortran 语言,推荐使用 |
可通过mpiicc -show来查看编译器的具体信息:
bash
[username@hnlogin02 ~]$ mpiicc -show 编译示例:
bash
[username@hnlogin02 ~]$ mpiifort -o main.exe main.f90
[username@hnlogin02 ~]$ mpiicc -o main.exe main.cIntel MPI 常用的编译参数:
-fast:最大化整个程序的速度,相当于:-ipo,-O3,-no-prec-div,-static,和-xHost。这里是所谓的最大化,还是需要结合程序本身使用合适的选项
-xHost:使用编译主机上可用的最高指令集和处理器生成指令,非intel cpu不可使用此参数。
-qopenmp:编译OpenMP程序,注意:只能在同一个节点的CPU上跑OpenMP程序
-O<级别>:设定优化级别,默认为O2,O与O2相同,推荐使用。O3为在O2基础之上增加更激进的优化,比如包含循环和内存读取转换和预取等,但在有些情况下速度反而慢,建议在具有大量浮点计算和大数据处理的循环时的程序使用
-Ofast:设置某些激进参数优化程序速度,相当于:-O3-no-prec-div
-m32和-m64:指定生成为IA32或Intel64架构的代码
-L<库目录>:指明库的搜索路径
-l<库文件>:指明需链接的库名,如库名为libxyz.a,则可用-lxyz指定
-shared:产生共享目标而不是可执行文件,必须在编译每个目标文件时使用-fpic选项
-static:静态链接所有库
-fpic、-fPIC和-fno -pic:是否生成位置无关代码。当生成共享代码时,必须添加
-align和-noalign:数据是否自然对齐
-mcmodel=mem_model:设定内存模型。mem_model可为:small:限制代码和数据在开始的2GB地址空间,默认medium:限制代码在开始的2GB空间,存储数据空间不受此限制large:对于代码和数据存储空间都无限制。
3.1.4 常见软件编译
1)传统configure/make:
传统configure/make方式需要通过configure;make;make install 3个步骤,比如下载和解压hdf5后,进入到源码目录:
bash
[username@hnlogin02 hdf5-1.12.0]$ module load compiler/intel/2017.5.239 ## 加载intel编译器
[username@hnlogin02 hdf5-1.12.0]$ module load mpi/intelmpi/2017.4.239 ## 加载Intel mpi 环境
[username@hnlogin02 hdf5-1.12.0]$ ./configure --help > help ## 打印configure的help信息
[username@hnlogin02 hdf5-1.12.0]$ vim help ## 查看configure的help信息
[username@hnlogin02 hdf5-1.12.0]$ ./configure --enable-fortran --enable-parallel CC=mpiicc FC=mpiifort CXX=mpiicpc \
--prefix=/public/home/$USER/soft/hdf5/1.12.0/intel-parallel-withfortran > configure.log 2>&1
[username@hnlogin02 hdf5-1.12.0]$ tail configure.log ## 查看configure的日志是否有报错
[username@hnlogin02 hdf5-1.12.0]$ make -j 8 > make.log 2>&1 ## 编译软件
[username@hnlogin02 hdf5-1.12.0]$ make install ## 安装软件说明:
1 如果源码包里没有configure文件,可参考源码目录中的README/INSTALL内容,用autoconf或bootstrap.sh 来生成configure文件。
2 有些源码包里直接有makefile/Makefile,不必再使用configure命令了。
3 有些makefile中include了一些配置文件(比如common.mk),或者需要从某个目录下拷贝对应文件,比如vasp需要从arch目录下文件要拷贝成makefile.include,需要根据需求和软件环境进行修改。
4 可以make -j N选择N个线程同时编译,但有些程序比如fortran的,有可能不能使用多线程编译。
5 有些软件Makefile中没有install的内容,编译完成后,可以直接配置PATH环境变量使用。
2) cmake方式
cmake是一个跨平台的安装编译工具,可以用简单的语句来描述所有平台的安装/编译过程。目前越来越多软件可以使用cmake来编译安装。软件源码解压后,源码目录一般会有CMakeLists.txt文件,来描述编译所需的各种环境变量和依赖,一般需要先参考软件编译文档README或者INSTALL来进行安装。cmake编译过程一般为:
cmake; make; make install 3个过程。
例如,下载和解压Gromacs-2021.3后:
bash
[username@hnlogin02 gromacs-2021.3]$ module load compiler/intel/oneapi-2021.1 #加载 oneapi环境
[username@hnlogin02 gromacs-2021.3]$ module load compiler/gnu/7.2.0 #加载高版本gcc
[username@hnlogin02 gromacs-2021.3]$ module load apps/cmake/3.22.1 #加载高版本cmake
[username@hnlogin02 gromacs-2021.3]$ mkdir build #创建编译目录
[username@hnlogin02 gromacs-2021.3]$ cd build
[username@hnlogin02 build]$ cmake -DCMAKE_INSTALL_PREFIX=/public/software/gromacs/2021.3/oneapi-2021.3 \
-DGMX_MPI=on -DGMX_OPENMP=on -DGMX_GPU=off -DGMX_BUILD_OWN_FFTW=ON -DCMAKE_C_COMPILER=mpiicc \
-DCMAKE_CXX_COMPILER=mpiicpc ../ > cmake.log 2>&1
[username@hnlogin02 build]$ vim cmake.log ##确认cmake有无报错信息。
[username@hnlogin02 build]$ make -j 8 > make.log 2>&1 ## 编译软件
[username@hnlogin02 build]$ make install ## 安装软件说明:
1 cmake并没有像./configure --help的查看编译参数的命令,因此建议在执行cmake前,建议参考软件的安装文档,根据文档添加参数。
2 cmake指定软件安装目的目录的参数是: -DCMAKE_INSTALL_PREFIX=/some/path/to/install
3 cmake指定编译器的参数是: -DCMAKE_C_COMPILER=XXX, -DCMAKE_CXX_COMPILER=XXX和
-DCMAKE_Fortran_COMPILER=XXX;
3.2 Conda软件安装
Conda是一个流行的开源版本管理和Python环境工具,支持多种操作系统,并包含了众多的科学计算、数据分析的软件和软件包,可轻松解决软件安装时需要的依赖环境。普通用户在没有管理员权限情况下,可以创建、安装和管理自己软件和虚拟python环境。
用户可以根据需求选择anaconda或者miniconda来使用。下面以miniconda为例介绍常用的使用方法。
3.2.1 安装miniconda3
可以选择官网或者国内镜像下载软件包:
bash
[username@hnlogin02 ~]$wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
[username@hnlogin02 ~]$wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh #或选清华镜像 下载修改权限进行安装:
bash
[username@hnlogin02 ~]$chmod +x Miniconda3-latest-Linux-x86_64.sh
[username@hnlogin02 ~]$./Miniconda3-latest-Linux-x86_64.sh #交互式安装,可根据需求设置安装目录 安装后,一般建议用户默认SSH登录后不激活base 环境,可用下面命令来设置:
bash
[username@hnlogin02 ~]$source ~/.bashrc
[username@hnlogin02 ~]$conda config --set auto_activate_base false 默认国外镜像如果使用较慢,可考虑使用国内镜像:https://mirrors.cernet.edu.cn/list/anaconda
比如清华的源设置请参考:https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/
3.2.2 创建和进入env环境
用户可以根据需要创建env环境:
bash
[username@hnlogin02 ~]$conda env create -n pysot python=3.7 #创建名称为pysot的环境,并安装版本为3.7的python
[username@hnlogin02 ~]$conda env create -f conda-env.yml #或者根据前期导出的yml文件来创建,并安装软件 查看当前conda已经有的env环境:
bash
[username@hnlogin02 ~]$conda env list 激活env环境:
bash
[username@hnlogin02 ~]$conda activate pysot3.2.3 安装/删除软件
在激活的env环境中,查看当前环境中已经安装的软件:
bash
(pysot) [username@hnlogin02 ~]$conda list 参考所需软件的安装文档进行安装,一般的安装软件命令为:
bash
(pysot) [username@hnlogin02 ~]$conda install -c ChannelName SoftwareName #例如: conda install -c bioconda gatk4
(pysot) [username@hnlogin02 ~]$conda install -c ChannelName SoftwareName=Version #指定软件包的版本,例如: conda install -c pytorch pytorch=1.10.1 考虑到有时conda seach的时间开销,一般建议用户在https://anaconda.org/查询所需软件的安装命令。
查看当前env环境的软件列表:
(pysot) [username@hnlogin02 ~]$conda list 删除软件:
bash
(pysot) [username@hnlogin02 ~]$conda remove -n EnvName SoftwareName #例如 conda remove -n pytorch tzdata
(pysot) [username@hnlogin02 ~]$conda remove -n EnvName --all #删除某个env环境的所有软件包3.3.4 退出env环境
当一个环境使用完,需要退出时,使用如下命令:
bash
(pysot) [username@hnlogin02 ~]$conda deactivate
[username@hnlogin02 ~]$3.3 python软件安装
对于某些特殊的python软件或软件包,在conda环境无法处理的情况下,可以选择源码安装python到用户目录,然后再安装python包。
3.3.1 源码安装python3
安装命令例如:
bash
[username@hnlogin02 ~]$wget https://www.python.org/ftp/python/3.9.6/Python-3.9.6.tar.xz
[username@hnlogin02 ~]$tar -xvf Python-3.9.6.tar.xz;
[username@hnlogin02 ~]$cd Python-3.9.6
[username@hnlogin02 Python-3.9.6]$./configure --prefix=/public/home/$USER/soft/python3.9.6-gcc485/ --enable-shared
[username@hnlogin02 Python-3.9.6]$make ; make install 安装后进行环境设置,下面export命令可写到一个文件py3env.sh中,再用source py3env.sh加载环境:
bash
[username@hnlogin02 ~]$cat py3env.sh
export PATH=/public/home/$USER/soft/python3.9.6-gcc485/bin:$PATH
export LD_LIBRARY_PATH=/public/home/$USER/soft/python3.9.6-gcc485/lib/:$LD_LIBRARY_PATH
export PKG_CONFIG_PATH=/public/home/$USER/soft/python3.9.6-gcc485/lib/pkgconfig:$PKG_CONFIG_PATH
[username@hnlogin02 ~]$source py3env.sh 环境加载后,可使用pip3来安装所需的软件包,pip3能比较方便的解决依赖包的安装,比如:
bash
[username@hnlogin02 ~]$pip3 install pysam
[username@hnlogin02 ~]$pip3 install numpy
#如果需要使用国内镜像,可参考:
[username@hnlogin02 ~]$pip3 install scipy -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com3.3.2 源码安装python2
安装命令例如:
bash
[username@hnlogin02 ~]$wget https://www.python.org/ftp/python/2.7.18/Python-2.7.18.tar.xz
[username@hnlogin02 ~]$tar -xvf Python-2.7.18.tar.xz;
[username@hnlogin02 ~]$cd Python-2.7.18
[username@hnlogin02 Python-2.7.18]$./configure --prefix=/public/home/$USER/soft /python2.7.18-gcc485 \
--enable-shared --with-ensurepip
[username@hnlogin02 Python-2.7.18]$make; make install 安装后进行环境设置,下面export命令可写到一个文件py2env.sh中,再用source py2env.sh加载环境:
bash
[username@hnlogin02 Python-2.7.18]$cat py2env.sh
export PATH=/public/home/$USER/soft /python2.7.18-gcc485/bin:$PATH
export LD_LIBRARY_PATH=/public/home/$USER/soft /python2.7.18-gcc485/lib/:$LD_LIBRARY_PATH
export PKG_CONFIG_PATH=/public/home/$USER/soft /python2.7.18-gcc485/lib/pkgconfig:$PKG_CONFIG_PATH
[username@hnlogin02 Python-2.7.18]$ source py2env.sh 环境加载后,可使用pip来安装所需的软件包,pip能比较方便的解决依赖包的安装,比如:
bash
[username@hnlogin02 ~]$pip install pysam
[username@hnlogin02 ~]$pip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple ## 使用国内镜像
[username@hnlogin02 ~]$pip install statsmodels==0.10.1 ## 指定安装包版本3.4 perl软件安装
集群默认的perl版本为5.16.3,为方便用户perl包的安装和使用,集群系统默认安装了perl-homedir包,设置了如下的环境变量:
bash
PERL5LIB="/public/home/$USER/perl5/lib/perl5"
PERL_LOCAL_LIB_ROOT="/public/home/$USER/perl5"
PERL_MB_OPT="--install_base /public/home/$USER/perl5"
PERL_MM_OPT="INSTALL_BASE=/public/home/$USER/perl5" 用户可以根据需要安装perl包到用户家目录下,不再需要root权限。
如果需要其他版本的perl,可以通过conda或者源码安装来使用,如果不需要上述的环境变量,可以用unset来取消设置:
bash
[username@hnlogin02 ~]$ unset PERL5LIB PERL_LOCAL_LIB_ROOT PERL_MB_OPT PERL_MM_OPT3.4.1 conda安装perl
conda环境中使用perl比较简单,可使用如下命令:
bash
[username@hnlogin02 ~]$unset PERL5LIB PERL_LOCAL_LIB_ROOT PERL_MB_OPT PERL_MM_OPT
[username@hnlogin02 ~]$conda create -n perl534
[username@hnlogin02 ~]$conda activate perl534
(perl534) [username@hnlogin02 ~]$conda install perl=5.34.0 ##安装perl的包,可以在anaconda.org中搜索安装命令,进行安装3.4.2 源码安装perl
源码安装perl例如:
bash
[username@hnlogin02 ~]$unset PERL5LIB PERL_LOCAL_LIB_ROOT PERL_MB_OPT PERL_MM_OPT
[username@hnlogin02 ~]$wget https://www.cpan.org/src/5.0/perl-5.36.0.tar.gz --no-check-certificate
[username@hnlogin02 ~]$tar -xvf perl-5.36.0.tar.gz
[username@hnlogin02 ~]$cd perl-5.36.0
[username@hnlogin02 perl-5.36.0]$./Configure -Dusethreads -Dprefix=/public/home/$USER/soft /perl-5.36-gcc485 -de
[username@hnlogin02 perl-5.36.0]$make; make test; make install 安装后需要设置环境变量,可写到一个perl_env.sh文件中,再进行source生效:
bash
[username@hnlogin02 ~]$cat perl_env.sh
export PATH=/public/home/$USER/soft /perl-5.36-gcc485/bin:$PATH
export PERL5LIB=/public/home/$USER/soft /perl-5.36-gcc485/lib/perl5:$PERL5LIB
[username@hnlogin02 ~]$ source perl_env.sh 为了使用cpanm安装perl包,需要安装App-cpanminus,例如:
bash
[username@hnlogin02 ~]$wget https://cpan.metacpan.org/authors/id/M/MI/MIYAGAWA/App-cpanminus-1.7046.tar.gz
[username@hnlogin02 ~]$tar -xvf App-cpanminus-1.7046
[username@hnlogin02 ~]$cd App-cpanminus-1.7046
[username@hnlogin02 App-cpanminus-1.7046]$perl Makefile.PL
[username@hnlogin02 App-cpanminus-1.7046]$make install 使用cpanm安装perl包,可以使用国内的源:
bash
cpanm --mirror https://mirrors.tuna.tsinghua.edu.cn/CPAN Parallel::ForkManager
cpanm --mirror https://mirrors.aliyun.com/CPAN Bio::Perl3.5 R软件安装
R是一个用于统计计算和图形的免费软件环境,在生物信息学、统计学等领域内非常流行。集群公共目录安装了R-4.2.1版本,并安装了常用的R包,用户可使用module load apps/R/4.2.1-gcc910加载使用。
3.5.1 conda安装
conda安装R比较简单:
bash
[username@hnlogin02 ~]$conda create -n R421
[username@hnlogin02 ~]$conda activate R421
(R421) [username@hnlogin02 ~]$conda install -c conda-forge r-base=4.2.1 使用conda安装R包时,建议先anaconda.org中搜索下安装命令,一般是以”r-“开头命名的,比如R包Seurat,使用conda安装时的名称是:r-seurat, 安装命令为:
bash
[username@hnlogin02 ~]$conda install -c conda-forge r-seurat3.5.2 源码安装
源码安装命令例如:
bash
[username@hnlogin02 ~]$module load compiler/gnu/9.1.0 ##也可以选择需要的编译器版本
[username@hnlogin02 ~]$module load mathlib/pcre2/10.37-gnu485 ## R-4.2.1版本需要的依赖软件;
[username@hnlogin02 ~]$wget https://cloud.r-project.org/src/base/R-4/R-4.2.1.tar.gz
[username@hnlogin02 ~]$tar -xvf R-4.2.1.tar.gz
[username@hnlogin02 ~]$cd R-4.2.1
[username@hnlogin02 R-4.2.1]$./configure --prefix /public/home/$USER/soft/R-4.2.1-gnu910 --enable-R-shlib \
CPPFLAGS=-I/public/software/mathlib/pcre2/10.37-gcc485/include
[username@hnlogin02 ~]$make -j 8; make install R安装好后,R包的安装方法一般有两种方法:
1 进入R软件,使用install.packages(“PackageName”)、 devtools::install_github(“githubacct/Name”),或者第三方的工具比如BiocManager::install(“PackageName”)来安装包。
2 如果软件下载有问题,R也支持用户上传安装包,通过命令R CMD INSTALL PackageName.tar.gz来安装。
4 作业提交
本集群使用中科曙光Gridview提供的优化和改进版的slurm作业调度系统。SLURM是一个开源、容错和高度可扩展的集群管理和作业调度系统,适用于大型和小型Linux集群。
建议用户以作业脚本的方式提交作业,如果有临时作业需求,也可以通过交互式提交作业。
4.1 常用命令
普通用户常用的slurm命令有:
| 命令 | 说明 |
|---|---|
| sbatch | 像SLURM调度系统提交作业脚本 |
| salloc | 请求一个交互式作业的资源 |
| srun | 启动某个APP软件的一个或多个(MPI)进程 |
| scancel | 取消正在运行或排队的作业 |
| squeue | 查看当前用户提交的作业状态(包括排队,运行,正在退出等状态的任务) |
| sinfo | 查看当前集群中用户可用节点的总体状态 |
| scontrol | 查看slurm集群的作业、节点、队列等的详细信息 |
| sacct | 查看当前和历史作业的信息,(查询slurm历史数据库信息) |
4.1.1 sbatch
用户可使用sbatch命令提交一个作业脚本到调度系统,命令语法为:
sbatch [OPTIONS(0)...] [ : [OPTIONS(N)...]] 脚本名称 [args(0)...]
比如提交一个sbatch_wrf.sh脚本:
bash
[username@hnlogin02 ~]$ cat sbatch_wrf.sh
#!/bin/bash ## slurm脚本需要的脚本解析程序
#SBATCH -J wrftest ## 作业的名称:wrftest
#SBATCH -N 5 ## 作业申请节点数为:5个计算节点
#SBATCH -p c6148 ## 作业申请的队列是:c6148
#SBATCH --exclusive ## 作业使用的计算节点为独占,排除其他作业影响
#SBATCH -n 196 ## 作业申请的并行作业task数为:196
#SBATCH --mem 30G ## 作业申请单节点的内存限制为30GB
#SBATCH -o %x_%j.out ## 作业stdout输出文件为: 作业名_作业id.out
#SBATCH -e %x_%j.err ## 作业stderr 输出文件为: 作业名_作业id.err
module purge ## 清空module环境
module load compiler/intel/2017.5.239
module load mpi/intelmpi/2017.4.239
module load mathlib/netcdf/4.4.1-intelmpi2017
module load mathlib/hdf5/1.8.20-intelmpi2017
module load mathlib/pnetcdf/1.11.2-intelmpi2017 ##加载上述所需要的module 环境
ulimit -s unlimited
srun ./wrf.exe.Optimize ## 使用srun来启动并行wrf.exe进程
[username@hnlogin02 ~]$ sbatch sbatch_wrf.sh
Submitted batch job 2905
[username@hnlogin02 ~]$ sbatch的常用参数:
| 参数 | 说明 |
|---|---|
| --job-name 或-J | 作业的名称 |
| --partition或-p | 作业申请的队列名称 |
| --nodes 或-N | 作业申请的计算节点个数 |
| --ntasks 或-n | 作业总的task数量(可以理解为mpi的总进程数) |
| --ntasks-per -node | 作业在每个计算节点的task数量 |
| --cpus-per-task | 作业每个task使用的cpu核心数量(适用于多线程openmp作业) |
| --mem | 作业每个计算节点申请的内存数量,单位可以是M、G等 |
| --gres | 作业申请资源,可用于申请gpu,例如--gres=gpu:8 申请单节点8个gpu卡 |
| --time=HH:MM:SS或-t | 限制作业的运行时间,默认为分钟,超过限制时间,slurm会杀掉作业 |
| --exclusive | 作业申请的节点属性为独占,slurm不在分配其他作业到同一个计算节点 |
| --output=/path2dir/filename或-o | 作业的标准输出stdout的输出文件 |
| --error=/path2dir/filename或-e | 作业的标准错误stderr的输出文件 |
| --nodelist=<node1..nodeX> 或-w | 设置作业在node list描述的节点上运行 |
| --exclude=<node1..nodeY> 或-x | 设置作业不在node list描述的节点上运行 |
说明 :
1 sbatch的命令行参数,是可以以#SBATCH作为开头的参数,在作业脚本中设置的,例如sbatch_wrf.sh中的#SBATCH -N 5和#SBATCH -n 196参数,与sbatch -N 5 -n 196 sbatch_wrf.sh是一样的,需要注意的是:如果命令行的参数和脚本中的#SBATCH参数有冲突,命令行的参数会覆盖掉作业脚本中的参数。
2 建议用户将参数写到作业脚本中,方便后续查看的使用。
3 若使用独占参数 -- exlusive,在作业计费时是按照节点的全部CPU核心和GPU卡来计费的,请用户知悉。
4 详细的参数和使用文档,请参考man sbatch 或者 https://slurm.schedmd.com/sbatch.html 。
4.1.2 salloc
用户使用salloc命令为作业申请计算节点,命令语法为:
salloc [OPTIONS(0)...] [ : [OPTIONS(N)...]] [command(0) [args(0)...]]
用户可以使用salloc来提交交互式的作业:
1 使用为作业申请资源,当资源申请到后,会系统会反馈作业id和计算节点信息;
2 用户可以ssh登录到计算节点,进行计算;
3 操作完成后,需要手工scancel掉作业(或者在salloc时设置运行时间,时间截止自动退出)。
例如:
bash
[username@hnlogin02 ~]$ salloc -p c6148 -N 1 -n 1
salloc: Pending job allocation 2911
salloc: job 2911 queued and waiting for resources
salloc: job 2911 has been allocated resources
salloc: Granted job allocation 2911
salloc: Waiting for resource configuration
salloc: Nodes c199 are ready for job ## 调度系统为作业2911号,分配c199节点
[username@hnlogin02 ~]$ ssh c190 ## 其他节点是登录不上去的,
Access denied by pam_slurm_adopt: you have no active jobs on this node
Authentication failed.
[username@hnlogin02 ~]$ ssh c199
[username@c199 ~]$
…….
[username@c199 ~]$exit
[username@ hnlogin02 ~]$scancel 2911 salloc的常用参数与sbatch的参数类似,请参考man salloc帮助文档或 https://slurm.schedmd.com/salloc.html 。
4.1.3 srun
用户使用srun命令来启动并行作业,命令语法为:
srun [OPTIONS(0)... [executable(0) [args(0)...]]] [ : [OPTIONS(N)...]] 执行程序 (N) [args(N)...]
参考4.1.1 sbatch中的sbatch_wrf.sh中的使用方式,在作业脚本中使用srun来启动运行MPI并行作业。
此外,由于srun执行并行程序时,如果没有分配计算资源,是会自动分配计算资源的。因此,srun可以作为交互式作业的提交命令,比如:
bash
[casdao@hnlogin02 ~]$ srun -p c6148 -N 1 -c 4 --pty bash -i ## 提交申请1个节点4个cpu核心的作业
srun: job 2917 queued and waiting for resources
srun: job 2917 has been allocated resources
[casdao@c199 ~]$ squeue ## 分配作业后,已经切换到计算节点c199
JOBID PARTITION NAME STATE TIME NODES CPUS MIN_MEM NODELIST(REASON)
2917 c6148 bash RUNNING INVALID 1 4 4.50G c199
[casdap@c199 ~]$./someAPPprograms -t 4 ## 运行计算程序
….
[casdao@c199 ~]$ exit ## 退出当前节点和作业
exit
[casdao@hnlogin02 ~]$说明:
1 srun 申请计算资源的参数与sbatch的参数类似,具体可参考man srun帮助文档。
2 srun 的--pty参数是打开虚拟终端模式执行0号task任务,且在虚拟终端执行bash -i的命令。
3 srun 提交交互作业后,待作业分配资源后,自动从登录节点切换到计算节点了,不必像salloc那样,需要手动ssh到计算节点;同样,在退出计算节点后,作业也就中断和退出了,不必像salloc那样需要scancel来取消作业。
4 更详细的使用请参考man srun 帮助文档,或者https://slurm.schedmd.com/srun.html
4.1.4 scancel
用户使用scancel来取消排队或运行中的作业或者作业step,命令语法为:
scancel [OPTIONS...] [job_id[_array_id][.step_id]] [job_id[_array_id][.step_id]...]
常用的参数有:
| 参数 | 说明 |
|---|---|
| <jobid> | 取消作业id为jobid的作业 |
| --user=username或-u | 取消属于username用户的作业 |
| --name=JobName或-n | 取消作业名称为JobName的作业 |
| --state=RUNNING|PENDING或-s | 取消作业状态为运行或者排队的作业 |
| --nodelist=node1,node2…或 -w | 取消在某个节点列表上的作业 |
| --partition=partition_name或-p | 取消partition_name队列上的作业 |
更详细的请参考man scancel帮助文档,或者https://slurm.schedmd.com/scancel.html
4.1.5 squeue
用户可以使用squeue查看已经提交的作业信息,命令语法为:
squeue [OPTIONS...]
squeue常用的参数有:
| 参数 | 说明 |
|---|---|
| --jobs=jobid或-j jobid | 查看作业id为jobid的作业信息(或者以逗号分割的id列表) |
| --user=username或-u username | 查看username用户的作业信息 |
| --name=<name_list>或-n <name_list> | 查看作业名称为JobName的作业信息 |
| --states=<state_list>或-t <state_list> | 查看作业状态为某类的作业信息,可使用缩写PD、R、CG等 |
| --nodelist=node1,node2…或 -w | 查看在某个节点或者节点列表上的作业信息 |
| --partition=ptname或-p ptname | 查看队列名称为ptname队列上的作业信息 |
| --sort=<sort_list> 或 -S <sort_list> | 以sort_list排序来查看作业信息,比如以作业jobid排序 -Si |
squeue作业的输出自选是可以自定义的,可以使用-o(字段缩写)或者-O(字段)参数,常用的有:
| -o参数 | -O参数 | 说明 |
|---|---|---|
| %i | jobid | 作业的jobid或者job step id |
| %P | partition | 作业使用的队列名称 |
| %j | name | 作业的名称 |
| %u | username | 作业所属的用户名称 |
| %T | state | 作业的状态信息 |
| %M | timeused | 作业已经运行的时间 |
| %l | timelimit | 作业的时间限制 |
| %D | numnodes | 作业申请使用的节点个数 |
| %C | numcpus | 作业申请使用的cpu核心总数 |
| %m | minmemory | 作业申请的min-memory内存大小 |
| %R | nodelist | 排队作业的排队原因,或者运行作业的节点列表 |
如果不希望每次squeue都使用-o或者-O的参数来指定输出,可以使用环境变量SQUEUE_FORMAT(对应-o参数)或者SQUEUE_FORMAT2(对应-O参数),例如:
bash
export SQUEUE_FORMAT="%.10i %.15P %.10j %.20u %.8T %.10M %.12l %.5D %.5C %.3H %.3I %.7m %R"
#export SQUEUE_FORMAT2="jobid:12,username:18,name:10,partition:.10,timeused:.12,numnodes:.7,numcpus:.7, nodelist:.25" 常见的作业状态有:
| 状态缩写 | 状态信息 | 说明 |
|---|---|---|
| CA | CANCELLED | 状态为取消,被用户或者管理员取消 |
| CD | COMPLETED | 状态为完成,退出码为0 |
| CF | CONFIGURING | 状态为配置,作业已经被分配了计算资源,等待资源可以被使用 |
| CG | COMPLETING | 状态为正在完成,长时间的CG状态,可能是计算节点存储卡顿 |
| NF | NODE_FAIL | 状态为失败,由于某个或某些计算节点故障导致 |
| PD | PENDING | 状态为排队,如果reason是priority,是由于前面还有排队作业;如果reason是resource,表明资源不足,资源满足申请时会立即运行 |
| R | RUNNING | 状态为运行,作业正在运行中 |
说明:
1 为了保护用户的作业信息私密性,集群设置了slurm的PrivateData参数,普通用户只能查看到自己账号的作业信息。
2 更详细的使用请参考man squeue帮助文档,或者https://slurm.schedmd.com/squeue.html
4.1.6 sinfo
用户使用sinfo来查看集群的队列信息和节点状态,命令语法为:
sinfo [OPTIONS...]
常用的参数有:
| 参数 | 说明 |
|---|---|
| --summarize或-s | 查看集群队列的整体summarize信息 |
| --partition=<part>或者-p <part> | 查看某个队列part的信息 |
| --list-reasons或者-R | 查看集群中有故障、下线、离线等不可用状态的节点信息 |
| --Node或者 -N | 以节点名导向来输出 |
| --nodes=<nodes> 或者-n | 查看某个节点所属的队列信息 |
| --format= 或者-o | 以简要的方式指定输出格式 |
| --Format= 或者-O | 指定输出格式 |
查看队列空闲节点的信息,可使用sinfo -s,该命令输出中的NODES(A/I/O/T),节点状态信息:
| 节点状态缩写 | 节点状态 | 说明 |
|---|---|---|
| A | allocated | 节点cpu核心全部被分配,没有空闲可用的核心 |
| I | idle | 节点空闲,没有分配任何作业 |
| O | other | 节点下线、或者故障等状态,无法提供计算服务 |
| T | total | 某个队列节点的总个数 |
更详细的使用请参考man sinfo帮助文档,或者https://slurm.schedmd.com/sinfo.html
4.1.7 scontrol
用户通过scontrol命令查看队列、节点、作业等详细信息,在有权限情况下可修改部分作业属性,命令语法为:
scontrol [OPTIONS...] [COMMAND...]
普通用户常用的命令有:
| Scontrol子命令 | 参数 | 说明 |
|---|---|---|
| show | partition | 查看某个/所有队列的配置信息:scontrol show partition <partition_name> |
| show | node | 查看某个节点的配置信息:scontrol show node <node_hostname> |
| show | Job | 查看正在调度或运行中某个作业的详细信息:scontrol show job JOBID |
| show | hostname | 查看某个节点列表包含哪些节点: scontrol show hostname node[62-66] |
| update | job | 在有权限的情况下,修改作业的某些信息。比如: 降低某个作业的优先级:scontrol update job=7742 nice=500 ; 修改某个作业的jobname : scontrol update JobID=21845_2 name=Arturo |
| hold | JOBID | 将某个排队的作业状态设置为hold,暂不排队运行,例如:scontrol hold 1151 |
| release | JOBID | 将hold的作业恢复排队,例如:scontrol release 1151 |
| requeue | JOBID | 将某个正在运行的作业重新排队,重新运行,例如:scontrol requeue 1154 |
| requeuehold | JOBID | 将某个正在运行的作业重新排队,并设置为hold状态 |
更详细的使用请参考man scontrol帮助文档,或者https://slurm.schedmd.com/scontrol.html
4.1.8 sacct
用户使用sacct查看当前或历史作业的记账信息,通常是查询slurm的数据库或者记账日志,命令语法为:
sacct [OPTIONS...]
常用的参数有:
| 参数 | 说明 |
|---|---|
| --starttime 或者-S | 开始时间,格式为:YYYY-MM-DD[THH:MM[:SS]], |
| --endtime或者-E | 结束时间,格式同starttime,例如: "2022-10-01 23:59:59" |
| --format或者-o | 格式化输出需要的字段,例如统计机时: sacct -o cputimeraw |
| --helpformat或者 -e | 查看输出的字段信息 |
| --jobs=<jobid> 或者 -j | 查看作业id为jobid的作业历史信息 |
| --state=<state_list> 或者 -s | 查看作业状态为state_list的历史作业信息 |
| --allocations或者-X | 仅显示作业统计信息,不显示作业step信息 |
| --truncate 或者-T | 以-S或者-E的时间来截断作业的时间 |
如果用户需要统计某个时段(2022年10月)的总机时信息,可以参考:
bash
[username@hnlogin02 ~]$ sacct -X -T -S “2022-10-01 00:00:00” -E “2022-10-31 23:59:59” -o cputimeraw |awk ‘{sum+= $1}END{print sum/3600}’ 更详细的使用请参考man sacct帮助文档,或者https://slurm.schedmd.com/sacct.html
4.2 准备脚本
根据用户的不同计算需求,分别介绍以下几类slurm作业脚本。
4.2.1 串行作业脚本
如果用户的作业是串行作业,即使用单节点的一个cpu核心的作业,可参考如下的作业脚本:
bash
#!/bin/bash
#SBATCH -J your_job_name
#SBATCH -p your_queue
#SBATCH -N 1 ## 由于都是单节点的串行作业,-N请设置为1
#SBATCH -n 1 ## 由于都是单节点的串行作业,-n 请设置为1
#SBATCH -o %j.o
#SBATCH -e %j.e
/public/home/$USER/path/to/your_proc <options> ## 建议使用程序的绝对路径4.2.2 openmp并行作业
如果用户的作业是单节点多线程(openmp)作业,即使用单节点一个或多个cpu核心的作业,可参考如下作业脚本:
bash
#!/bin/bash
#SBATCH -J your_job_name
#SBATCH -p your_queue
#SBATCH -N 1 ## 由于都是单节点的openmp并行作业,-N请设置为1
#SBATCH -n 1 ## 由于都是单节点的openmp并行作业,-n 请设置为1
#SBATCH --cpus-per-task=24 ## 由于都是单节点的openmp并行作业,-c 可以根据需求设置,比如24
#SBATCH -o %j.o
#SBATCH -e %j.e
module load compiler/intel/2015.2.164
export OMP_NUM_THREADS=24 ## 根据需求,设置openmp作业运行所需要的环境变量
/public/home/$USER/path/to/your_openmp_proc <options>4.2.3 MPI并行作业
如果用户的作业是多节点MPI并行作业,即使用多节点的作业,可参考如下的作业脚本:
bash
#!/bin/bash
#SBATCH -J your_job_name
#SBATCH -p your_queue
#SBATCH -N 2 ## 根据计算需求,申请多个计算节点,比如-N 2
#SBATCH -n 48 ## 根据计算需求,申请总的MPI task数,比如-n 48
#SBATCH -o %j.o
#SBATCH -e %j.e
module load compiler/intel/2015.2.164
module load mpi/intelmpi/5.0.2.044 ## 加载并行程序编译时用到的MPI计算环境
srun ./your_mpi_proc ## 可以使用slurm的srun来启动并行任务
## modulefile 已经设置SLURM_MPI_TYPE=pmi2,可以不需要--mpi=pmi2
## mpirun -np 48 ./your_mpi_proc ## 也可以使用MPI环境的mpirun来启动并行任务说明:
1 常用的MPI环境大多可以自动从slurm调度系统获取节点列表hostfile和并行规模(-np进程数)等信息,所以在启动mpi任务时,可以不设置-np、-host、--hostfile、--machinefile等参数。
2 如果某些商业软件或者不能从slurm中获取hostfile等信息,可以在作业脚本中生成hostfile文件,比如:
bash
MACHINEFILE="nodes.$SLURM_JOB_ID"
srun -l /bin/hostname | sort -n | awk '{print $2}' > $MACHINEFILE
mpirun -np $SLURM_NTASKS -machinefile $MACHINEFILE ./your_mpi_proc4.2.4 MPI+openmp并行作业
为了最大限度的提升计算效率,有些软件可使用多节点进程+多线程的MPI+openmp并行作业,参考如下作业脚本:
bash
#!/bin/bash
#SBATCH -J your_job_name
#SBATCH -p your_queue
#SBATCH -N 2
#SBATCH -n 4
#SBATCH --ntasks-per-node=2
#SBATCH --cpus-per-task=12
#SBATCH -o %j.o
#SBATCH -e %j.e
module load compiler/intel/2015.2.164
module load mpi/intelmpi/5.0.2.044
export OMP_NUM_THREADS=12
srun --mpi=pmi2 ./your_mpi_openmp_proc4.2.5 批量数组作业
针对批量相类似的用户作业,SLURM提供了作业数组的功能。目前作业数组只支持批量作业,且这些批量作业是可以用一个变量来索引的,提交作业时使用sbatch的-a或者--array参数来指定,作业脚本中可以使用SLURM_ARRAY_TASK_ID等环境变量来索引。
例如:一个数组作业的200个输入参数,以每行一个参数的形式存在一个文件列表中,数组作业的脚本是:
bash
#!/bin/bash
#SBATCH -J JobArrayTest
#SBATCH -p c5320
#SBATCH -n 1 ## 每个子task程序运行需要申请的进程数
#SBATCH -N 1 ## 每个子task程序运行需要申请的计算节点数
#SBATCH --cpus-per-task=1 ## 每个子task程序运行需要申请的cpu核心数
#SBATCH -o %x_%A_%a.out ## 作业stdout文件名称: “作业名称_作业id_子作业task_id.out”
#SBATCH -e %x_%A_%a.err ## 作业stderr文件名称: “作业名称_作业id_子作业task_id.err”
#SBATCH -a 1-200 ## 数组作业的数组大小从1到200.
input=$(cat input.lst | sed -n ${SLURM_ARRAY_TASK_ID}p) ## 取输入参数文案中第TASK_ID行的内容
##file=$(ls input/*.txt | sed -n ${SLURM_ARRAY_TASK_ID}p) ## 如果输入文件在同一个的input目录下,选lsinput/*.txt 信息中的第TASK_ID个
/path/to/you/program.exe -i $input -o ${input}.out说明:
1 作业array的index可以使用“-”来指定范围:比如1-200的index是1,2,3….200;也可以用逗号“,”来指定任意的数字:比如0,6,16-32的index是0,6,16,17…32; 范围并不一定要从1开始,可以从任意数字开始,但建议用户采用方便管理的index。
2 可以在-a或--array后使用 %N来指定同时有N个作业在运行;例如 -a 1-100%10,即同时运行的作业数为10
3 更详细的使用可参考https://slurm.schedmd.com/job_array.html
4.2.6 作业依赖关系
用户可以根据计算需求,在提交作业时设置作业之间的依赖关系,通过各种逻辑关系的设置来完成较为复杂的业务处理流程。具体是使用sbatch命令中的--dependency或-d参数,常用的有:
| 参数 | 说明 |
|---|---|
| after:job_id[[+time][:jobid[+time]...]] | 依赖jobid的开始运行或被scancel后,开始运行 |
| afterany:job_id[:jobid...] | 依赖作业job_id全部完成后(退出码可以不为0),开始运行, |
| afterok:job_id[:jobid...] | 依赖作业job_id正常(退出码为0)结束后,开始运行 |
| afternotok:job_id[:jobid...] | 依赖作业job_id报错(退出码为非0,节点故障或者超时)结束后,开始运行 |
例如,提交作业的脚本:
bash
#! /bin/bash
job1=` sbatch job1.sh | awk '{print $4}' `
job2=` sbatch -d afterok :${job1} job2.sh | awk '{print $4}' `
job3=` sbatch -d afterok :${job2} job3.sh | awk '{print $4}' `
echo "Job ids are $job1 , $job2 , $job3 "4.3 作业提交
4.3.1 脚本提交
用户根据自己计算需求,参考4.2中的脚本和参数,准备作业脚本后,使用sbatch命令来提交作业:
bash
[username@hnlogin02 ~]$ sbatch slurm_job_script.sh 作业提交后,slurm会返回一个作业id,可用于后期作业记账信息的查询。
查看当前作业情况,可参考: 4.1.5 squeue章节
查看历史作业信息,可参考: 4.1.8 sacct章节。
4.3.2 交互式作业
目前集群提供两种方式的交互作业:
1) salloc方式: 使用salloc为作业申请资源,当资源申请到后ssh登录到计算节点,进行计算,计算完成手动scancel掉作业(或者在salloc时设置运行时间,时间截止自动退出)。 详情可参考4.1.2 salloc章节.
2) srun方式: 使用如下命令提交,详情可参考4.1.3 srun章节:
bash
srun -p 队列名称 -N 节点数量 -n 任务数量 --gres=gpu:1 --pty bash -i5 结果查看
用户提交作业,待作业运行后,可以随时查看作业的stdout和stderr输出信息,也可以查看作业程序自己输出的日志信息。
如果需要实时查看文件的输出日志,可以使用tail 命令:
bash
tail -f slurm_jobid.out ## 退出查看时,使用ctrl +c 命令 建议用户不定期查看作业输出、关注作业运行状态,如果作业日志中有报错,有可能影响后续正常运行,尽量终止作业,以免造成机时和机时费的浪费。
6 常见问题
6.1 如何长时间保持一个登录的shell窗口
建议使用screen命令来创建一个terminal终端会话,如果出现网络中断,或需要将命令放在后台执行,或临时退出(比如下载数据)等会失去与登录节点的连接,可以再次登录节点,回到前面screen命令创建的terminal会话,简单的使用步骤:
1 开启screen:screen -S Name,打开一个名为Name(任意取名)的session。
2 如果希望是保留这个session的退出,使用ctrl +a +d,保存退出。
3 再次回到前面的session,可先screen -ls查看需要恢复session的PID或Name。
4 使用screen -r PID/Name回到指定的session。如果session是attached状态,要用screen -d -r PID/Name。
5 如果要退出这个session,在这个session中使用exit退出。
此外,若出现某些错误,无法开启或恢复到原先的session,可以使用 screen -wipe 来清理故障的session。更多详细信息,请参考screen的文档:man screen。
6.2 同组用户之间数据如何读写
普通用户可以通过chmod命令,设置自己目录的权限,来达到让同组用户访问的目的。比如,设置目录为750,同组用户会对文件或目录有==读和执行==的权限:
bash
chmod 750 fileORdir 设置为770:同组用户会有==写==文件或目录的权限。
chmod 770 fileORdir 请注意,不要将用户家目录设置为 777 模式。因为用户家目录下的.ssh目录,关系到账号在平台所有节点计算节点间ssh免密登录。如果将家目录设置为777,其他用户可修改家目录下的.ssh目录,包括秘钥信息等,openssh视为账号不安全,无法在节点间免密登录,直接影响用户秘钥登录,并行作业的运行,甚至输出文件的传输等。
例如,USERA用户要访问同组USERB用户家目录下的Data目录。 用户UserB不要把/public/home/USERB目录设置为777,而设置为750,此时USERA用户就可以进入到/public/home/USERB目录;在对Data目录设置为所需的权限,比如770,USERA就有Data目录的写权限了。
6.3 如何使用命令行查看账号的磁盘配额
集群中存储系统暂时没有提供可实时查看磁盘配额的标准命令,管理员在登陆节点设置了一个命令get_quota,供用户查看自己账号的用户/组配额,例如:
[casdao@hnlogin02:~]$get_quota
Quota_type Name Used Limit
GROUP casdao 3.52616TB 10TB
[casdao@hnlogin02:~]$get_quota2
Quota_type Name Used Limit
USER casdap 9.69366TB 0B
[casdao@hnlogin02:~]说明:
1 配额信息并不是实时的,配额信息更新间隔是5分钟。
2 用户可是根据自己的家目录来选择对应的get_quota工具,如果家目录为/public2/home开头,使用get_quota2,如果是/public/home开头,使用get_quota命令。
6.4 公网如何数据下载
集群的登录节点是与Internet联通的,用户可以在登录节点上通过网络安装软件和软件包,也可以使用命令行下载公网数据,常用的命令有curl或wget,详细请参考man curl或man wget 。
如果用户要下载某个网站目录下的所有数据,可参考如下的wget参数:
bash
wget -c --random-wait -t 0 -r -p -np -k -e robots=off https://ftp.1000genomes.ebi.ac.uk/vol1/ftp/data_c/...... /working/HG...GRCh38/ 如果使用wget时需要每次都加--no-check-certificate参数,可以在家目录下的.wgetrc中,设置:
bash
[username@hnlogin02 ~]$ echo "check-certificate=off" >> ~/.wgetrc6.5 module load加载报错conflict with XXX
当用户module加载环境的时候,偶尔会出现如下类似的报错,加载不上:
ERROR:150: Module 'mpi/intelmpi/2017.4.239' conflicts with the currently loaded module(s) 'mpi/openmpi/3.1.4-inte2017'
ERROR:102: Tcl command execution failed: conflict mpi 原因是当前已经加载一个了mpi环境,管理员设置modulefile不可重复加载mpi,以免造成环境不统一,导致作业跑不起来或者报错。 用户可选择unload/purge清理当前环境后重新加载,或使用switch 切换需要的环境:
[casdao@hnlogin02 ~]$ module list ## 查看当前环境
Currently Loaded Modulefiles:
1) compiler/intel/2017.5.239 2) mpi/openmpi/3.1.4-inte2017
[casdao@hnlogin02 ~]$ module switch mpi/openmpi/3.1.4-inte2017 mpi/intelmpi/2017.4.239 ## 切换环境
[casdao@hnlogin02 ~]$ module list
Currently Loaded Modulefiles:
1) compiler/intel/2017.5.239 2) mpi/intelmpi/2017.4.239
[casdao@hnlogin02 ~]$6.6 普通用户如何使用 sudo apt-get install安装软件
HPC集群一般不为用户提供sudo权限。根据HPC的软硬件架构,用户家目录所在的目录是共享目录,即所有计算节点都可以访问。 因此,软件只需在用户家目录安装一次,即可在任意计算节点上运行;同时,用户对自己家目录是有读写权限的,只需在软件安装时指定安装目录为家目录即可。
软件安装指定安装目录,一般可以在configure时用--prefix,或cmake时用 -D CMAKE_INSTALL_PREFIX来设置,具体请参考软件的安装文档。
此外,apt-get是ubuntu或者debian等操作系统的软件包管理命令,不适合本集群的CentOS操作系统。一般管理员在部署集群时已经将必要的安装包装好,如果需要安装或升级操作系统的软件包,请联系管理员,管理员会酌情予以解决。
6.7 编译软件找不到库文件/头文件
使用module load 加载的环境一般设置了程序运行时需要的环境变量,这些环境变量在程序编译阶段,有可能不会被编译器或者编译脚本使用,如果出现编译报错,一般需要用户在makefile或者配置文件中进行修改:
1 找不到库:需要指定库的路径, -L/public/some/path/to/lib (lib目录下就可以ls出来库文件)
比如 -llapack ,库文件文件在/A/B/C/lib/liblapack.so ,指定参数为:-L/A/B/C/lib
说明:有些时候,-llapack报错找不到,但lib目录下确实有liblapack.so;此时需要确认是否是有-static等参数,如果有,是需要liblapack.a静态库文件。
2 找不到头文件:需要指定头文件路径: -I/public/some/path/to/include (大写的i)
比如代码是:#include <antlr/Token.hpp> ,Token.hpp文件前有一个路径,需要指定到antlr的上一层目录,头文件在/A/B/C/include/antlr/Token.hpp, 需要指定路径为; -I/A/B/C/include/
另外: #include “parms3.h” 引号的情况,是加载当前目录下的头文件。
6.8 编译软件链接时有函数未定义
当软件编译到最后时,将众多.o对象文件链接到一起时,出现“undefined reference to XXXXX”的报错,一般是编译链接的库名称不太对:可以上网或者去依赖软件的lib目录,搜一下函数在哪个库中定义,然后增加或修改链接的库名称。
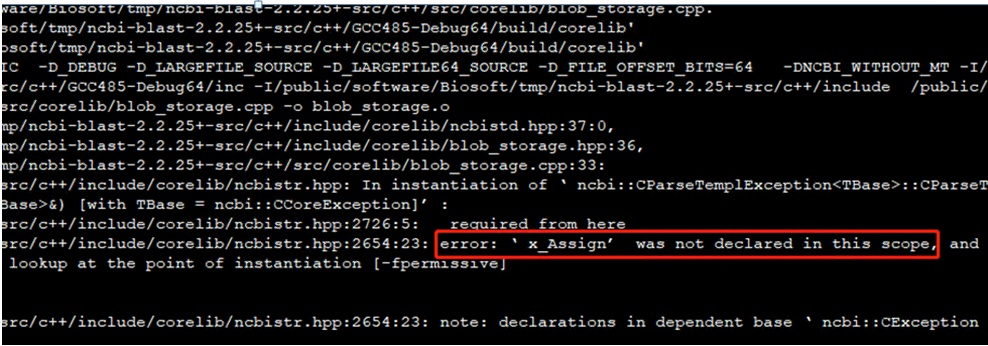
例如下图的报错,虽然编译链接了-lnetcdf,但依然报错。经过查找,未定义的函数是在libnetcdff.so中,将-lnetcdf修改为-lnetcdff后,编译通过。

6.9 C++程序编译报错在scope/namespace里未定义、未声明
此类报错大多是编译器版本不兼容,需要更换更高/低的编译器版本,一般软件安装说明里会提到需要的环境。
6.10 如何查看账号可使用的队列
一般销售同事或管理员会以邮件/微信的方式,通知用户可用的队列信息。用户也可以自行查看,使用avail_partitions脚本命令:
[casdao@hnlogin01 ~]$ avail_partitions
PartitionName=a100
PartitionName=c6148
PartitionName=c7542
[casdao@hnlogin01 ~]$ avail_partitions6.11 作业提交后不运行
作业任务后,作业一直排队,排队原因是QOSMaxCpuPerUserLimit,说明作业申请的计算资源,超过了账号允许的最大CPU限制,需要根据用户计算需求,或调小并行规模,或联系销售同事或管理员设置更大规模。
bash
[casdao@hnlogin02 ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
1927310 c7542 cas casdao PD 0:00 1 (QOSMaxCpuPerUserLimit)
1927309 c7542 cas casdao PD 0:00 1 (QOSMaxCpuPerUserLimit)
1927308 c7542 cas casdao PD 0:00 1 (QOSMaxCpuPerUserLimit)
1927288 c7542 cas2 casdao R 40:05 1 d008
[casdao@hnlogin02 ~]$ 作业排队常见原因和说明:
| 原因 | 说明 | 解决方法 |
|---|---|---|
| BeginTime | 作业未到达指定的任务开始时间 | 等待或调整开始时间 |
| Dependency | 作业运行所依赖的条件未满足 | 一般等待满足条件 |
| InvalidAccount | 用户的账号没有使用该队列的权限 | 调整申请的队列,或联系管理员处理 |
| JobHeldAdmin | 作业被管理员挂起, | 联系管理员处理 |
| JobHeldUser | 作业被用户挂起 | 用户视情况自行恢复resume |
| PartitionTimeLimit | 作业申请的运行时间超过队列时间限制 | 调整运行时间,联系管理员处理 |
| Priority | 有更高优先级的作业在排队 | 等待作业运行,特殊情况联系管理员处理 |
| QOSMaxCpuPerUserLimit | 用户使用的最大cpu核心数限制 | 等待前面作业运行完,或调整CPU并行规模 |
| QOSMaxGRESPerUser | 用户使用的最大GPU卡数限制 | 等待前面作业运行完,或调整GPU并行规模 |
| Resources | 作业排队的队列没有空闲资源 | 等待作业运行或切换队列 |
| ReqNodeNotAvail | 作业申请的节点部分或全部不可用 | 等待作业运行,或联系管理员处理 |
6.12 作业报错内存OOM
作业退出后,一般需要查看作业的运行日志,如果日志中有killed或者slurmstepd: error: Detected XX oom-killd等字样,可以用sacct查看下作业的退出状态,如果是OUT_OF_MEMORY,原因是作业实际使用的内存超过了申请的内存,slurm调度系统将作业进程杀掉。用户需要根据程序和输入参数,重新估计作业运行需要的内存大小,申请内存。
例如:2830作业,在运行了7小时候,oom报错退出,用sacct查询结果如下:
bash
[root@hnlogin02 ~]# sacct -j 1846230
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
1846230 xhpl_6148 c6148 casdao 40 OUT_OF_ME+ 0:125
1846230.batch batch casdao 40 OUT_OF_ME+ 0:125
1846230.extern extern casdao 40 OUT_OF_ME+ 0:125
1846230.0 pmi_proxy casdao 40 OUT_OF_ME+ 0:125
[root@hnlogin02 ~]# 其中作业申请了每节点的内存为ReqMem:187005MB,调度系统监测到的MaxRss为185732284KB,中间略有差距是因为最后一次内存监测之后,作业继续运行,使用的内存超过了申请内存,进程被杀掉了,被杀掉时的RSS未被监测记录下来。
如果作业退出状态是FAILED或COMPLETE,但作业日志中确实有Killed字样,且作业输出异常,可联系管理员查看系统日志,有可能是用户在作业脚本中申请了不限制内存 #SBATCH --mem 0,在实际过程中,由于内存几乎占满计算节点,被操作系统杀掉。这种情况下,如果是并行程序,可以独占节点,且减少单节点的tasks数量 (--tasks-per-node),如果仍未解决,请联系销售或管理员,切换更大内存的节点或集群。
目前集群各队列设置了核心配比一定内存策略,通过申请一定数量的cpu核心,来匹配作业所需的内存。
bash
[root@hnlogin02 ~]# scontrol show part c7542 |grep Mem
DefMemPerCPU=3948 MaxMemPerNode=UNLIMITED ##每核心匹配3948MB内存
[root@hnlogin02 ~]# scontrol show part c6148 |grep Mem
DefMemPerCPU=4608 MaxMemPerNode=UNLIMITED 假如作业使用c6148,作业需要1核心20GB,需要申请的核心数为5:
bash
#SBATCH -N 1
#SBATCH -n 5 ##或者 #SBATCH -c 56.13 作业运行异常缓慢
用户在作业分配资源并开始运行后,是有权限ssh 计算节点上查看作业运行情况的。如果发现作业运行异常缓慢,登录计算节点后,用free、top和dstat命令查看到节点负载很高,但cpu利用率较低,节点还有一部分free的内存,但dstat的Paging in和Paging out数量很高,例如下图所示:
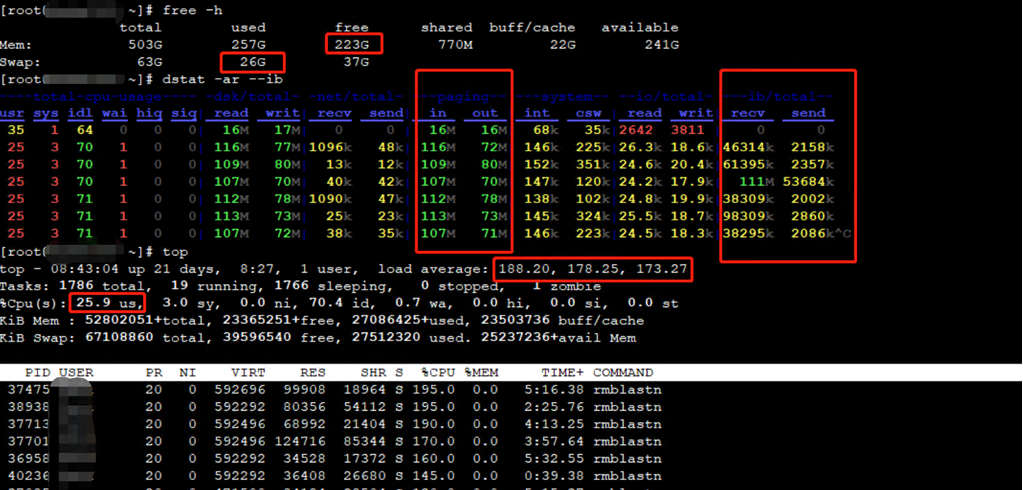
这是因为作业申请的内存不足,当作业进程使用完申请的内存后,再申请更多内存时,计算节点将进程的部分内存数据存交换到swap分区来腾出内存空间,swap分区一般是计算节点本地磁盘或者本地ssd硬盘,频繁的swapin和swapout数据,造成节点负载较高,cpu利用较低,作业运行异常缓慢。
解决办法:用户可以根据作业的内存需求,申请合理的内存大小来进行计算。
6.14 MPI程序报错
MPI并行程序相对来说是比较复杂的计算程序,如果配置不当会出现各种问题。一般MPI程序需要加载某个MPI环境,从源码进行编译。 运行时,也需要加载相同的MPI环境。如果出现报错:
bash
Fatal error in PMPI_Comm_rank: Invalid communicator 一般是编译和运行时的mpi环境不一致,比如,使用openmpi编译的程序,而调用intel mpi的mpirun来运行的。
建议用户确认编译和运行时加载的是相同的编译环境,并将环境加载写到作业脚本中,方便后续查看。
如果用户使用intel-mpi编译Fortran程序运行时出现运行错误,可参考List of Run-Time Error Messages查询错误码对应的解释和说明: https://www.intel.com/content/www/us/en/develop/documentation/fortran-compiler-oneapi-dev-guide-and-reference/top/compiler-reference/error-handling/run-time-errors/list-of-run-time-error-messages.html

6.15 作业报错退出且无日志文件和内容
导致作业退出,没有日志信息的原因可能有2个:
1 作业设置的stdout和stderr文件的目录不存在,导致作业日志无法写入。
#SBATCH -o log/%x_%j.out.log ##其中log目录不存在,会导致无输出日志文件 解决办法:在工作目录创建log目录,或者在设置-o 日志文件时,去掉log目录。
2 用户的磁盘配额,在作业运行期间超限,导致无法创建或写入日志文件和任何报错信息。
解决办法:清理相关不需要的数据,或者联系销售同事和管理员增加存储配额。
6.16 用户执行squeue或sbatch很慢,很卡
出现squeue或者sbatch等slurm命令执行很卡顿的情况,可联系系统管理员或支持工程师反馈。
一般导致slurm命令执行卡顿的原因包括:slurm调度系统的服务节点故障(包括网络故障和节点故障),或者slurm主服务收到的请求太多,响应缓慢导致的。
以往运维的经验中,遇到过用户将squeue等需要与slurm管理服务slurmctld通信的命令,写成循环脚本,频繁和长时间的执行,导致slurm主服务负载很高,影响正常作业的提交、分配资源等操作。
因此,建议用户不要频繁的将slurm命令编辑为脚本,循环或一直执行,管理员监控到,或收到其他用户反馈,会杀掉此类操作的进程。
6.17 作业运行超时被杀掉,如何运行长时间作业
目前集群各队列中,配置作业运行的最长时间是不限制的。
为了避免用户提交作业后,忘记查看结果或不在关注作业,而导致运行时间超长,带来机时和金额的浪费,队列中设置了作业运行的默认时间为15天。
如果用户作业提交没有设置时间限制,运行15天后,作业会被调度系统杀掉。如果用户需要设置更长时间,可以在提交作业时设置运行时间,比如:
bash
#SBATCH -t 30-00:00:00 ## 例如设置运行时间为30天 如果用户提交的作业运行一段时间,发现时间限制不够长,还需要继续运行,可以联系管理员延长作业运行时间的限制,不必中断作业,重新设置参数来提交作业运行。查看作业运行时间和时间限制的命令:
[root@hnlogin01 ~]# export SQUEUE_FORMAT="%.10i %.15P %.10j %.20u %.8T %.10M %.12l %.5D %.5C %.3H %.3I %.7m %R"
[root@hnlogin01 ~]# squeue -j 1527151,1527401
JOBID PARTITION NAME USER STATE TIME TIME_LIMIT NODES CPUS SOC COR MIN_MEM NODELIST(REASON)
1527151 c6148 c6148 XXXXXXX RUNNING 9:04:29 15-00:00:00 2 8 * * 4.50G c[054-055]
1527401 c7542 XXXXX XXXXXXXX RUNNING 2:32 30-00:00:00 1 21 * * 80G d015
[root@hnlogin01 ~]#6.18 登录节点的进程被杀掉
登录节点提供用户文本编辑、作业提交、程序编译、少量文件上传下载等轻量级操作,而科学计算等计算密集型任务和大文件校验等IO密集型任务,会占用较多资源,影响其他用户正常使用,因此登录节点禁止用户执行此类的“非法”计算任务。
集群管理员在收到其他用户反馈,或者看到有上述“非法”的进程,或者监控程序监控到达到阈值的“非法”进程, 会不定期、在不提前通知用户的情况下,Kill掉占用大量资源的计算进程,也请用户互相监督,相互理解。
6.19 如何使用图形界面计算
鉴于Linux图形界面相对缺乏稳健的特性,建议用户使用命令行提交计算任务。如果有特殊的图形计算需求,也可以使用VNC来登录和使用图形界面。具体方法是:
- 使用salloc提交作业申请,申请到计算资源;
- 登录到计算节点,使用vncserver开启计算节点vnc服务(如果申请多个节点,可选择其中一个登录)
- 通过用户电脑上的vnc客户端,连接到计算节点的图形界面,打开程序进行计算。 作业运行期间,可以退出用户电脑的vnc客户端,但不要中断vnc服务。
- 作业运行完后,退出电脑的vnc客户端,scancel取消掉作业。
例如:
- 申请作业:
[casdao@hnlogin01 ~]$ salloc -N 1 -p c6148 -n 1 -t 30 ## 设置时间限制为30分钟,用户可根据需求自行设置
salloc: Pending job allocation 1527733
salloc: job 1527733 queued and waiting for resources
salloc: job 1527733 has been allocated resources
salloc: Granted job allocation 1527733
salloc: Waiting for resource configuration
salloc: Nodes c041 are ready for job
[casdao@hnlogin01 ~]$- 申请的计算节点为c041,可登录到计算节点,使用vncserver命令开启vnc图形界面:
bash
[casdao@hnlogin01 ~]$ ssh c041
Warning: Permanently added 'c041,12.2.50.41' (ECDSA) to the list of known hosts.
[casdao@c041 ~]$ vncserver -geometry 1440x900 ## 首次开启,需要设置一个vnc登录的密码,用来从电脑客户端登录
You will require a password to access your desktops.
Password:
Verify:
Would you like to enter a view-only password (y/n)? n
A view-only password is not used
New 'c041:1 (casdao)' desktop is c041:1
Creating default startup script /public/home/casdao/.vnc/xstartup
Creating default config /public/home/casdao/.vnc/config
Starting applications specified in /public/home/casdao/.vnc/xstartup
Log file is /public/home/casdao/.vnc/c041:1.log
[casdao@c041 ~]$ ps -ef |grep vnc ## 查看vnc端口号,一般-rfbport 后面需要用到的端口号:5901
casdao 144244 1 1 21:28 pts/0 00:00:00 /usr/bin/Xvnc :1 -auth /public/home/casdao/.Xauthority -desktop c041:1 (casdao) -fp catalogue:/etc/X11/fontpath.d -geometry 1440x900 -httpd /usr/share/vnc/classes -pn -rfbauth /public/home/casdao/.vnc/passwd -rfbport 5901 -rfbwait 30000
casdao 144282 1 0 21:28 pts/0 00:00:00 /bin/sh /public/home/casdao/.vnc/xstartup
casdao 144983 139457 0 21:28 pts/0 00:00:00 grep --color=auto vnc
[casdao@c041 ~]$ grep -w c041 /etc/hosts ## 查看计算节点的IP地址为 12.2.50.41
12.2.50.41 c041
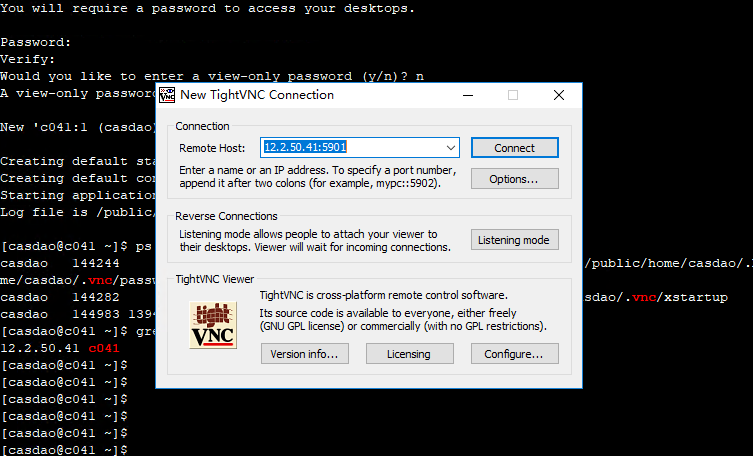
[casdao@c041 ~]$- 通过window 的vnc客户端(这里使用tightvnc客户端 www.tightvnc.com ),连接计算节点c041的vnc: RemoteHost填写: 12.2.50.41:5901,点击connect,输入刚才vncserver首次开启时设置的密码,即可登录计算节点的图形界面:
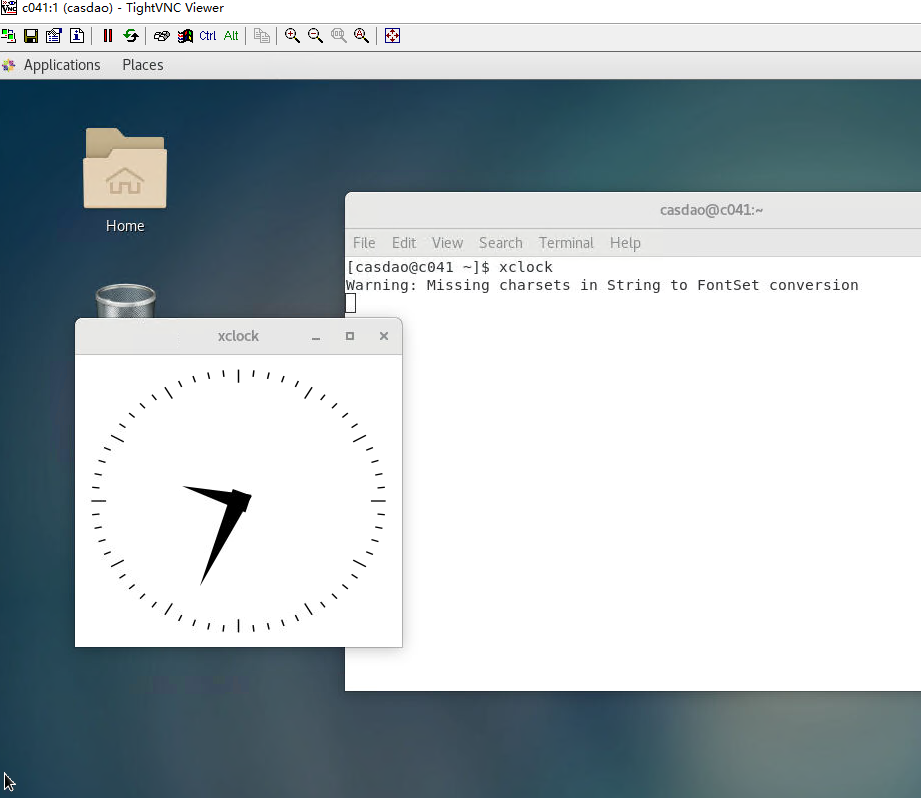
在vnc界面中,右键打开一个terminal,执行xclock命令,打开一个图形的钟表测试,会出现如下图的钟表窗口。 这里用户可执行相关的计算任务,直至计算结束。
作业运行完,请关闭图形界面,关闭vnc客户端登录,在c041节点的命令行执行删除vnc的命令:
bash[casdao@c041 ~]$ vncserver -list ## 查看vnc的display_id TigerVNC server sessions: X DISPLAY ## PROCESS ID :1 144244 [casdao@c041 ~]$ vncserver -kill :1 ## 删掉id为1的display Killing Xvnc process ID 144244 [casdao@c041 ~]$ exit ## 退出计算节点 logout Connection to c041 closed. [casdao@hnlogin01 ~]$ squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 1527733 c6148 interact casdao R 14:01 1 c041 [casdao@hnlogin01 ~]$ scancel 1527733 ## 删除作业id为1527733的作业 [casdao@hnlogin01 ~]$ salloc: Job allocation 1527733 has been revoked. [casdao@hnlogin01 ~]$
6.20 致谢模板
(中文)本论文的计算结果得到了算力互联(北京)科技有限公司的支持和帮助;
(英文)The computations in this paper were run on the HPC cluster supported by casdao (Beijing) Technology Co., LTD
7 Linux基础命令
7.1 浏览目录命令
ls [options] [directory]
ls -la —— 给出当前目录下所有文件的一个长列表,包括以句点开头的隐藏文件。
ls -l *.doc —— 列出当前目录下以字母.doc 结尾的所有文件。
ls -a —— 显示当前目录所有文件及目录。
ls -t —— 将文件依建立时间之先后次序列出。
ls -ltr s* —— 列当前目录下任何名称是 s 开头的文件,越新的文件排越后。
7.2 切换目录命令
cd [directory]
cd ~ —— 切换到用户家目录。
cd /tmp —— 切换到目录/tmp。
cd .. —— 切换到上一层目录
cd / —— 切换到系统根目录
7.3 浏览文件命令
cat [textfile] 显示文本文件内容
cat /etc/hosts —— 显示文本文件 /etc/hosts 中的内容。
cat test.txt | more —— 逐页显示 test.txt 文件中的内容。
cat test.txt >>test1.txt —— 将 test.txt 的内容附加到 test1.txt 文件之后。
cat a.txt b.txt >readme.txt —— 将文件a.txt 和 b.txt 合并成 readme.txt 文件。
more [textfile] 和 less [textfile] 逐屏显示文本文件内容
head 和 tail 命令用于查看从文件头或文件尾开始的指定数量的行的内容。
vim 编辑文本文件。vim命令有三种模式,命令模式、输入模式及行编辑模式,编辑器常用的命令:
| 功能 | 进入编辑模式 | 退出编辑模式 | 保存文件 | 退出编辑器 | 退出不保存 | 删除字符 | 删除整行 | 拷贝整行 |
|---|---|---|---|---|---|---|---|---|
| 命令 | i, o,a, | Esc | :w | :q | :q! | x | dd | yy + p |
7.4 目录操作命令
pwd 显示用户目前所在的目录的绝对路径名称。
mkdir [-p] [directory] 创建目录
mkdir mydir —— 在当前目录下建立 mydir 目录。
mkdir -p one/two/three —— 在当前目录下建立指定的嵌套子目录。
rmdir [-p] [directory] 删除目录
rmdir mydir —— 删除“空”的子目录 mydir。
rmdir -p one/two/three —— 删除“空”的嵌套子目录 one/two/three。
注意:选项“-p”表示可以递归删除多层子目录,但删除的目录须为空目录,且须具有对该目录的写入权限。
7.5 文件操作命令
cp [source] [target] 复制文件
cp test1 test2 —— 将文件 test1 复制成新文件 test2。
cp test3 /home/bible/ —— 将文件 test3 从当前目录复制到/home/bible/目录中。
cp -r dir1(目录)dir2(目录) —— 复制目录 dir1 为目录 dir2。-r 参数表示递归。
注意:cp 命令默认将覆盖已存在的文件,加 -i 参数表示覆盖前将与用户交互。
mv [source] [target] 移动文件,文件改名
mv afile bfile —— 将文件 afile 改名成新文件 bfile。
mv afile /tmp —— 将文件 afile 从当前目录移动到/tmp/目录下。
mv afile ../ —— 将文件 afile 移动到上层目录。
mv dir1 ../ —— 将目录 dir1 移动到上层目录。
rm [files] 删除文件或目录
rm myfiles —— 删除 myfiles 文件。
rm * —— 删除当前目录下的所有未隐藏文件。
rm -f *.txt —— 强制删除所有以后缀名为 txt 文件。
rm -rf mydir —— 删除目录 mydir 以及其下的所有内容.
rm -I a* —— 删除当前目录下所有以字母a开头的文件,-i 选项表示将与用户交互。
注意:建议慎重使用 -rf选项,完全确认要删除的文件后,可以使用。
ln [-s] [source] [target] 建立链接
ln -s /usr/share/doc doc —— 创建链接文件doc,并指向目录/usr/share/doc。
ln -s afile linkafile —— 为文件afile 创建名为 linkafile 的软链接
ln afile bfile —— 为文件afile 创建名为 bfile 的硬链接
ln /usr/share/test hard —— 创建一个硬链接文件 hard,这时对于test文件对应的存储区域来说,又多了一个文件指向它。
touch [options] [filename] 新建一个文本文件
新建一个文本文件或修改文件的存取/修改的时间记录值。
touch * —— 将当前目录下的文件时间修改为系统的当前时间。
touch -d 20100101 test —— 将test文件的日期改为 2010 年 1 月 1 日。
touch abc —— 若abc文件存在,则修改为系统的当前时间;若不存在,则生成一个为当前时间的空文件。
scp [options] [[user@]host1:]sourcefile1 [[user@]host2:]destinationfile2 节点间传输数据
scp -r /A/B/file username@remote:/C/D/ —— 通过username账号使用ssh协议将本地file文件拷贝到remote节点的/C/D目录下;
scp -r username@remote:/A/B/dir /A/B/ —— 通过username账号使用ssh协议将remote节点的/A/B/dir目录拷贝到当前节点的/A/B/目录下
rsync [options] [USER@]HOST:SRC... [DEST] 同步本地或远程的数据
本地或远程的文件差量复制,不覆盖原有的相同文件,可以用于断点文件传输。
rsync -Parv /A/B/* /C/D —— 同步/A/B目录下的所有文件,到/C/D目录下,不删除不同的文件
rsync -Parv -e “ssh -i rsa -p XXX” user@ip:/A/B/sourcefile /C/D —— 通过ssh秘钥rsa和端口XXX,将ipaddress的/A/B目录下的sourcefile拷贝到本机的/C/D目录
7.6 文件目录权限命令
chmod [OPTION] MODE FILE 修改文件目录的读写执行的属性
Linux文件和目录属性有9个,分别是 owner/group/others(拥有者/组/其他) 三种身份,三种身份各有自己的 read/write/execute 权限。
| 权限 | 文字设定 | 数字设定 |
|---|---|---|
| 读 | R | 4 |
| 写 | W | 2 |
| 执行 | X | 1 |
其中,MODE是3个3个一组的,例如rwxrw-r--,前3个rwx是文件拥有者有所有权限,中间的rw-是同组用户读和写的权限,最后一组的r--是其他用户只有读的权限。
同时,MODE 可以用数字表示,将读写执行权限的数字相加,上述rwxrw-r--属性与764 等效。
普通用户可修改数据自己账号的目录和文件,如果要修改为其他这用户的属主,需要管理员权限。
7.7 帮助命令
man [command] 查看 command 命令的说明文档
man ls —— 查看ls命令的帮助信息
[command] -h 或 --help —— 查看[command]命令的帮助信息
info [command] 查看 command 命令的说明文档
7.8 打包/解包和压缩/解压缩命令
tar [options] [filename] 打包命令。
tar 命令常用参数:
-c:创建一个新 tar 文件
-v:显示运行过程的信息
-f:指定文件名
-z:调用 gzip 压缩命令进行压缩或解压
-j:调用 bzip2 压缩命令进行压缩或解压
-t:查看压缩文件的内容
-x:解开 tar 文件
-p:使用原文件的原来属性(属性不会依据使用者而变)
实例:
tar -cvf test.tar * —— 将所有文件打包成 test.tar,扩展名 .tar 需自行加上。
tar -zcvf test.tar.gz * —— 将所有文件打包并调用 gzip 命令压缩成为 test.tar.gz。
tar -tf test.tar —— 查看 test.tar 文件中包括了哪些文件。
tar -xvf test.tar —— 将 test.tar 文件解开。
tar -zxvf foo.tar.gz —— 将 foo.tar.gz 解压缩。
tar -jxvf foo.tar.bz2 —— 将 foo.tar.bz2 解压缩。
tar -cvf /tmp/etc.tar /etc —— 将整个/etc 目录下的文件全部打包成为 /tmp/etc.tar。
tar -zcvf /tmp/etc.tar.gz /etc —— 将整个/etc目录下的文件全部打包并调用用gzip命令压缩成为/tmp/etc.tar.gz。
tar -zxvpf /tmp/etc.tar.gz /etc —— 将/etc/内的所有文件备份下来,并且保存其权限。参数 -p 非常重要,尤其是当需要保留原文件的属性时!
7.9 其他常用命令
date 显示/修改当前的系统时间
date ——显示当前系统的时间及日期。
date 121010232009.10 —— 将时间更改为12 月10 日10 点23 分10 秒2009 年[月日时分年.秒]。
du [options] [directory or filename…] 显示指定的目录或文件所占用的磁盘空间。
du -h /home/username —— 查看username用户的目录下已经使用的容量大小。
find [options] [path...] [expression] 在目录下搜索文件或目录
find /A/B/dir -iname *.txt —— 在/A/B/dir目录下搜索所有文件名以.txt结尾的文件。
free 查看系统内存,虚拟内存(交换空间)的大小占用情况。
history 查看账号执行命令的历史记录,默认是保存1000条历史记录。
top 查看当前节点的使用信息。默认是交互的方式,使用ctrl+c或者q命令退出。
top -b -i -c -u user -n 5 —— 以非交互式,查看user用户的正在执行的命令,重复查询5次后退出。